第四章:智能指针
《Effective Modern C++》阅读笔记(四)
条款18:对于独占资源使用std::unique_ptr
std::unique_ptr是对裸指针的简单封装,有着和裸指针相同的尺寸,同时实现RAII特性。其实现的是对象专属所有权语义,不能被复制只能移动。
基于std::unique_ptr实现的工厂模式:
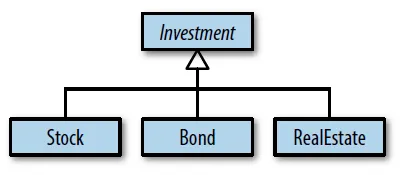
class Investment { … };
class Stock: public Investment { … };
class Bond: public Investment { … };
class RealEstate: public Investment { … };
template<typename... Ts> // 返回指向对象的std::unique_ptr,
std::unique_ptr<Investment> // 对象使用给定实参创建
Investment::makeInvestment(Ts&&... params);
{
…
auto pInvestment = // pInvestment是std::unique_ptr<Investment>类型
makeInvestment( arguments );
…
} // 销毁 *pInvestmentstd::unique_ptr对象超出作用于后默认调用delete析构对象所指向的对象,同时也支持自定义析构函数,自定义析构函数的传入参数需要时指向对象类型的裸指针,例如:
template<typename... Ts>
auto Investment::makeInvestment(Ts&&... params) // C++14返回值推导
{
auto delInvmt = [](Investment* pInvestment) // 现在在makeInvestment里
{
makeLogEntry(pInvestment);
delete pInvestment;
};
std::unique_ptr<Investment, decltype(delInvmt)>
pInv(nullptr, delInvmt);
if ( … )
{
pInv.reset(new Stock(std::forward<Ts>(params)...));
}
else if ( … )
{
pInv.reset(new Bond(std::forward<Ts>(params)...));
}
else if ( … )
{
pInv.reset(new RealEstate(std::forward<Ts>(params)...));
}
return pInv;
}不管makeInvestment实际创建的什么类型的对象,它最终在lambda表达式中,作为Investment*对象被删除。这意味着我们通过基类指针删除派生类实例,为此,基类Investment必须有虚析构函数:
class Investment {
public:
…
virtual ~Investment(); // 关键设计部分!
…
};最后std::unique_ptr可以转换成std::shared_ptr,但是不能反向转换:
std::shared_ptr<Investment> sp = // 将std::unique_ptr转为std::shared_ptr
makeInvestment(arguments);条款19:对于共享资源使用std::shared_ptr
与std::unique相反,std::shared_ptr实现的是对象共享所有权语义,同时在对象不被任何其他对象所有的时候进行析构。
引用计数
std::shared_ptr通过维护引用计算来实现复制和赋值操作:如果sp1使用sp2进行初始化,则二者指向对象的引用计数加1;而如果sp1和sp2之间使用赋值操作,即sp1=sp2,则sp1原来指向对象的引用计数减1,sp2指向对象的引用计数加1;如果sp1或者sp2超出作用域,则对应对象的引用计数减1。如果引用计数减为0,则该对象自动被析构(undefined behavior和double free问题的高发地)。
std::shared_ptr的存储结构为:
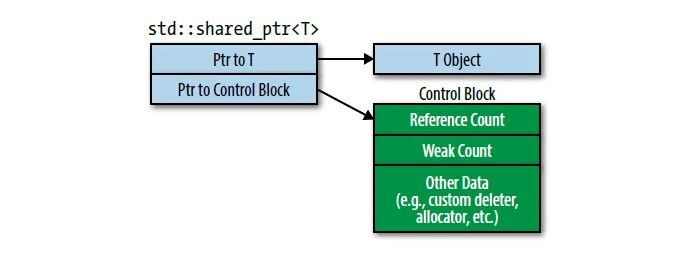
std::shared_ptr对象本身大小为两个指针:指向对象(T object)的裸指针和指向控制块(control block)的控制块指针。其中控制块中包含的内容有:
- 引用计数:原子类型,递增和递减都是原子操作,用来记录object被引用个数;
- 弱计数:
std::weak_ptr引用数,后文有介绍: - 其他数据:例如自定义析构函数,分配器等。
std::shared_ptr在多线程下可以保证引用计数的线程安全,但是保证不了所指对象的线程安全。
控制块的创建主要在以下几种情况:
- 使用
std::make_shared总是会创建一个控制块; - 从
std::unique_ptr出发初始化std::shared_ptr会创建控制块,创建完成后unique_ptr会被置空; - 从裸指针出发初始化
std::shared_ptr会创建控制块,创建完成后请不要再使用裸指针。
自定义析构函数
与std::unique_ptr类似,std::shared_ptr同样支持自定义析构函数,但是在定义时略有区别:unique_ptr的析构函数是智能指针类型的一部分,而shared_ptr则不是,如下例所示:
auto loggingDel = [](Widget *pw) // 自定义删除器
{
makeLogEntry(pw);
delete pw;
};
std::unique_ptr< // std::unique_ptr删除器类型是
Widget, decltype(loggingDel) // 智能指针类型的一部分
> upw(new Widget, loggingDel);
std::shared_ptr<Widget> // std::shared_ptr删除器类型不是
spw(new Widget, loggingDel); // 智能指针类型的一部分同一类型不同的析构函数的shared_ptr也被视为是同一种类型,例如:
auto customDeleter1 = [](Widget *pw) { … }; // 自定义删除器,
auto customDeleter2 = [](Widget *pw) { … }; // 每种类型不同
std::shared_ptr<Widget> pw1(new Widget, customDeleter1);
std::shared_ptr<Widget> pw2(new Widget, customDeleter2);
std::vector<std::shared_ptr<Widget>> vpw{ pw1, pw2 };shared_from_this
需要在类对象的内部中获得一个指向当前对象的std::shared_ptr对象,可能会采用的做法是:
class Bad
{
public:
std::shared_ptr<Bad> getptr() {
return std::shared_ptr<Bad>(this); // (1)
}
~Bad() { std::cout << "Bad::~Bad() called" << std::endl; }
};
int main()
{
std::shared_ptr<Bad> bp1(new Bad()); // (2)
std::shared_ptr<Bad> bp2 = bp1->getptr(); // (3)
}代码(1)处使用this创建了一个新的shared_ptr对象及控制块,注意该控制块中的引用计数是1,如果*this本身就已经被另一个shared_ptr指向(即(2)中的bp1),则bp1和bp2指向相同的对象,但是各自都包含一个引用计数为1的控制块,这就导致会出现double free的情况。
正确的做法是:
struct Good : std::enable_shared_from_this<Good> // 注意这里的继承
{
public:
std::shared_ptr<Good> getptr() {
return shared_from_this(); // 使用shared_from_this()
}
~Good() { std::cout << "Good::~Good() called" << std::endl; }
};
int main()
{
{
std::shared_ptr<Good> gp1(new Good());
std::shared_ptr<Good> gp2 = gp1->getptr();
}
system("pause");
}std::enable_shared_from_this是一个模板基类,其中定义了一个函数std::shared_from_this,其在创建指向*this对象的shared_ptr前会检查是否已有*this对应的控制块:如果有则直接返回一个新的 shared_ptr,引用计数增加;如果没有则创建一个新的 shared_ptr 并将其存储在 shared_from_this 的内部成员中,然后返回这个 shared_ptr。
条款20:当std::shared_ptr可能悬空时使用std::weak_ptr
std::weak_ptr不是一个独立的指针,而是std::shared_ptr的一种补充。weak_ptr一般通过shared_ptr来创建,创建后的weak_ptr指向与shared_ptr指向相同的位置,但是不会影响shared_ptr控制块的引用计数,这带来的问题就是weak_ptr可能悬空,如下例所示:
auto spw = // spw创建之后,指向的Widget的
std::make_shared<Widget>(); // 引用计数(ref count,RC)为1。
std::weak_ptr<Widget> wpw(spw); // wpw指向与spw所指相同的Widget。RC仍为1
spw = nullptr; // RC变为0,Widget被销毁。
// wpw现在悬空判断weak_ptr是否悬空的方法为:
wpw.expired();weak_ptr可以创建对应的shared_ptr,然后通过判断返回的shared_ptr指针来判断是否悬空:
std::shared_ptr<Widget> spw1 = wpw.lock(); // 如果wpw过期,spw1就为空
auto spw2 = wpw.lock(); // 同上,但是使用autoweak_ptr的主要用途是解决shared_ptr的循环引用问题:考虑一个持有三个对象A、B、C的数据结构,A和C共享B的所有权,因此持有std::shared_ptr,同时B还保存有A的所有权,如下图所示:

如果B使用shared_ptr保存对A的引用,这会使得A和B相互引用,最终导致AB无法成功析构造成内存泄漏。解决办法就是B对A的引用换为weak_ptr,但是B在访问A时需要先确认是否悬空。
条款21:优先考虑使用std::make_unique和std::make_shared,而非直接使用new
std::make_shared和std::make_unique只是将参数包完美转发到索要创建的对象的构造函数中,然后返回对应的指针类型:
template<typename T, typename... Ts>
std::unique_ptr<T> make_unique(Ts&&... params)
{
return std::unique_ptr<T>(new T(std::forward<Ts>(params)...));
}创建智能指针的方式有两种,使用make函数和使用new运算符创建:
auto upw1(std::make_unique<Widget>()); // 使用make函数
std::unique_ptr<Widget> upw2(new Widget); // 不使用make函数
auto spw1(std::make_shared<Widget>()); // 使用make函数
std::shared_ptr<Widget> spw2(new Widget); // 不使用make函数适用make系列函数构造情形
情形一:避免潜在内存泄漏
函数processWidget按照某种优先级处理Widget:
void processWidget(std::shared_ptr<Widget> spw, int priority);函数computePriority用来计算优先级:
int computePriority();如果使用new运算符:
processWidget(std::shared_ptr<Widget>(new Widget), // 潜在的资源泄漏!
computePriority());由于在运行时一个函数的实参必须先被计算,然后才能执行函数体,所以在调用processWidget之前会执行:
new Widget在堆上创建了Widget对象;- 负责管理
new出来指针的std::shared_ptr<Widget>构造函数必须被执行; - 执行
computePriority。
但实际上编译器会对上述过程进行重排:
new Widget在堆上创建了Widget对象;- 执行
computePriority; - 负责管理
new出来指针的std::shared_ptr<Widget>构造函数必须被执行。
不幸的是第2步执行computePriority时发生了异常,导致新分配的Widget并没有被shared_ptr接管,进而造成内存泄漏。
而如果使用make函数,则没有类似的问题:
processWidget(std::make_shared<Widget>(), // 没有潜在的资源泄漏
computePriority());情形二:避免多次内存分配
使用new创建shared_ptr会进行两次内存分配:对象分配和控制块内存分配。
std::shared_ptr<Widget> spw(new Widget);而使用make_shared则会分配一整块内存单块(single chunck),包含对象和控制块:
auto spw = std::make_shared<Widget>();不适用make系列函数构造情形
使用自定义构造器
如果智能指针需要使用自定义构造器,则只能采用new构造形式:
auto widgetDeleter = [](Widget* pw) { … };
std::unique_ptr<Widget, decltype(widgetDeleter)>
upw(new Widget, widgetDeleter);
std::shared_ptr<Widget> spw(new Widget, widgetDeleter);构造函数匹配问题
如果类的构造函数存在重载,分为std::initializer_list类型作为参数和非作std::initializer_list类型的参数构造,此时如果用大括号创建的对象更倾向于使用前者,而用小括号创建对象将调用后者构造函数。对于使用make系列函数创建方法,则可能无法创建出对应的类型。
如下例所示,创建的分别是指向一个包含10个元素,每个元素都是20的std::vector对象的unique_ptr和shared_ptr。
auto upv = std::make_unique<std::vector<int>>(10, 20);
auto spv = std::make_shared<std::vector<int>>(10, 20);但是如果想要创建一个只包含10和20的vector对象则必须要使用vector。
高内存占用对象以及生命周期就的weak_ptr
前面提到make_shared系列函数会比new要少分配一次内存,原因在于指向的对象和控制块位于同一块连续的内存区域。当对象的引用计数降为0,对象被销毁(即析构函数被调用)。但是因为控制块和对象被放在同一块分配的内存块中,直到控制块的内存也被销毁,对象占用的内存才真正被释放。
控制块中包含了引用计数和弱引用计数。前者用来记录有多少std::shared_ptr指向控制块,后者用来记录有多少shared_ptr和std::weak_ptr指向控制块。
class ReallyBigType { … };
auto pBigObj = //通过std::make_shared
std::make_shared<ReallyBigType>(); //创建一个大对象
… // 创建std::shared_ptrs和std::weak_ptrs
// 指向这个对象,使用它们
… // 最后一个std::shared_ptr在这销毁,
// 但std::weak_ptrs还在
… // 在这个阶段,原来分配给大对象的内存还分配着
… // 最后一个std::weak_ptr在这里销毁;
// 控制块和对象的内存被释放直接只用new,一旦最后一个std::shared_ptr被销毁,ReallyBigType对象的内存就会被释放:
class ReallyBigType { … }; // 和之前一样
std::shared_ptr<ReallyBigType> pBigObj(new ReallyBigType);
// 通过new创建大对象
… // 像之前一样,创建std::shared_ptrs和std::weak_ptrs
// 指向这个对象,使用它们
… // 最后一个std::shared_ptr在这销毁,
// 但std::weak_ptrs还在;
// 对象的内存被释放
… // 在这阶段,只有控制块的内存仍然保持分配
… // 最后一个std::weak_ptr在这里销毁;
// 控制块内存被释放条款22:当使用Pimpl惯用法,请在实现文件中定义特殊成员函数
Pimpl(pointer to implementation)指的是将类数据成员替换成一个指向包含具体实现的类(或结构体)的指针,并将放在主类(primary class)的数据成员们移动到实现类(implementation class)去,而这些数据成员的访问将通过指针间接访问。
Pimpl的好处是将类的嵌套关系进行解耦,减少编译时间。举个例子,类Widget的定义如下:
class Widget() { // 定义在头文件“widget.h”
public:
Widget();
…
private:
std::string name;
std::vector<double> data;
Gadget g1, g2, g3; // Gadget是用户自定义的类型
};因为类Widget的数据成员包含有类型std::string,std::vector和Gadget,必须引入#include <string>,<vector>以及gadget.h。这些头文件将会增加类Widget使用者的编译时间,并且让这些使用者依赖于这些头文件。如果一个头文件的内容变了,类Widget使用者也必须要重新编译。
如果改成Pimpl的形式则不会存在这个问题,因此pImpl是一个指向不完全类型的指针,与类Impl的具体实现无关:
/********** widget.h *********/
class Widget
{
public:
Widget();
~Widget(); // 析构函数在后面会分析
…
private:
struct Impl; // 声明一个实现结构体
Impl *pImpl; // 以及指向它的指针
};
/********** widget.cpp *********/
#include "widget.h"
#include "gadget.h"
#include <string>
#include <vector>
struct Widget::Impl { // 含有之前在Widget中的数据成员的
std::string name; // Widget::Impl类型的定义
std::vector<double> data;
Gadget g1,g2,g3;
};
Widget::Widget() // 为此Widget对象分配数据成员
: pImpl(new Impl)
{}
Widget::~Widget() // 这里非常重要
{ delete pImpl; } // 需要析构指针,不然会内存泄漏具有自动内存管理特性的std::unique_ptr看起来天然适合做这种工作,如果上述Pimpl类修改为如下则会发生错误:
/********** widget.h *********/
class Widget {
public:
Widget();
…
private:
struct Impl;
std::unique_ptr<Impl> pImpl; // 使用智能指针而不是原始指针
};
/********** widget.cpp *********/
#include "widget.h"
#include "gadget.h"
#include <string>
#include <vector>
struct Widget::Impl { // 跟之前一样
std::string name;
std::vector<double> data;
Gadget g1,g2,g3;
};
Widget::Widget() // 通过std::make_unique
: pImpl(std::make_unique<Impl>()) // 来创建std::unique_ptr
{}
// unique_ptr不需要析构函数
/********** test.cpp *********/
#include "widget.h"
Widget w; // 错误!错误的原因在于当对象w被析构时(例如离开了作用域),其析构函数被调用。由于没有为unique_ptr声明一个析构函数,编译器会自动生成默认析构函数,使用delete来销毁内置于unique_ptr的原始指针。而在使用delete之前会通过static_assert来确保原始指针指向的类型不是一个不完整类型。此处显然static_assert检查会失败,这通常是错误信息的来源。这些错误信息只在对象w销毁的地方出现,因为类Widget的析构函数,正如其他的编译器生成的特殊成员函数一样,是暗含inline属性的。错误信息自身往往指向对象w被创建的那行,因为这行代码明确地构造了这个对象,导致了后面潜在的析构。
解决这个问题只需要确保在编译器生成销毁std::unique_ptr<Widget::Impl>的代码之前,Widget::Impl已经是一个完整类型即可。成功编译的关键就是在widget.cpp文件内,让编译器在看到Widget的析构函数实现之前先定义Widget::Impl:
/********** widget.h *********/
class Widget {
public:
Widget();
~Widget(); //只有声明语句
…
private:
struct Impl;
std::unique_ptr<Impl> pImpl; // 使用智能指针而不是原始指针
};
/********** widget.cpp *********/
#include "widget.h"
#include "gadget.h"
#include <string>
#include <vector>
struct Widget::Impl { // 跟之前一样
std::string name;
std::vector<double> data;
Gadget g1,g2,g3;
};
Widget::Widget() // 跟之前一样
: pImpl(std::make_unique<Impl>())
{}
Widget::~Widget() // 析构函数的定义
{}
// 或者
Widget::~Widget() = default; // 同上述代码效果一致但是声明一个类Widget的析构函数会阻止编译器生成移动操作,所以想要支持移动操作还要声明相关的函数。如果按以下方式实现:
/********** widget.h *********/
class Widget {
public:
Widget();
~Widget(); //只有声明语句
Widget(Widget&& rhs) = default; // 思路正确,
Widget& operator=(Widget&& rhs) = default; // 但代码错误
…
private:
struct Impl;
std::unique_ptr<Impl> pImpl; // 使用智能指针而不是原始指针
};编译器生成的移动赋值操作符,在重新赋值之前,需要先销毁指针pImpl指向的对象。然而在Widget的头文件里,pImpl指针指向的是一个不完整类型,所以这种做法还是会导致错误,对此解决的办法与前面类似:
/********** widget.h *********/
class Widget {
public:
Widget();
~Widget(); //只有声明语句
Widget(Widget&& rhs); //只有声明
Widget& operator=(Widget&& rhs);
…
private:
struct Impl;
std::unique_ptr<Impl> pImpl; // 使用智能指针而不是原始指针
};
/********** widget.cpp *********/
struct Widget::Impl { … }; // 跟之前一样
Widget::Widget() // 跟之前一样
: pImpl(std::make_unique<Impl>())
{}
Widget::~Widget() = default; // 跟之前一样
Widget::Widget(Widget&& rhs) = default; // 这里定义
Widget& Widget::operator=(Widget&& rhs) = default;如果将unique_ptr换成std::shared_ptr则完全没有上述问题:
/********** widget.h *********/
class Widget {
public:
Widget();
… // 没有析构函数和移动操作的声明
private:
struct Impl;
std::shared_ptr<Impl> pImpl; // 用std::shared_ptr
}; // 而不是std::unique_ptr
/********** widget.cpp *********/
Widget w1;
auto w2(std::move(w1)); // 移动构造w2
w1 = std::move(w2); // 移动赋值w1unique_ptr和shared_ptr在pImpl指针上的表现上的区别的深层原因在于支持自定义删除器的方式不同。unique_ptr删除器的类型是智能指针对象本身的一部分,这让编译器有可能生成更小的运行时数据结构和更快的运行代码。带来的限制就是unique_ptr指向的类型,在编译器的生成特殊成员函数(如析构函数,移动操作)被调用时,必须已经是一个完整类型。而shared_ptr删除器的类型不是该智能指针的一部分而是控制块的一部分,在对象析构器前控制块存在则所指的对象一定存在,因此当编译器生成的特殊成员函数被使用的时候,指向的对象不必是一个完整类型。